
1. Introducción
En el desarrollo profesional con Python, la organización del proyecto resulta crítica para garantizar mantenibilidad, escalabilidad y claridad. En entornos reales, las aplicaciones no se construyen como scripts aislados, sino como sistemas modulares capaces de integrar APIs, bases de datos y procesos de datos.
Se plantea una estructura base orientada a backend, procesamiento de datos y despliegue profesional.
2. Objetivo del diseño
- Separar responsabilidades (API, lógica, datos).
- Facilitar pruebas y refactorización.
- Permitir integración con PostgreSQL, Kafka y sistemas externos.
- Preparar despliegue en Docker y entornos cloud.
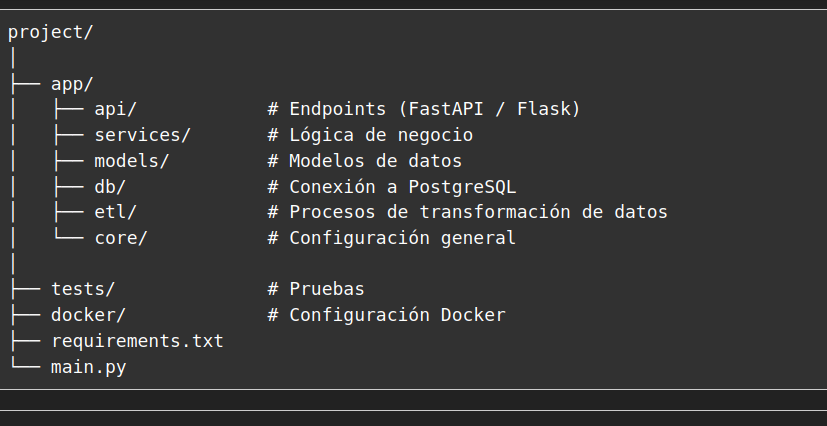
3. Estructura del proyecto
project/ │ ├── app/ │ ├── api/ # Endpoints (FastAPI / Flask) │ ├── services/ # Lógica de negocio │ ├── models/ # Modelos de datos │ ├── db/ # Conexión a PostgreSQL │ ├── etl/ # Procesos de transformación de datos │ └── core/ # Configuración general │ ├── tests/ # Pruebas ├── docker/ # Configuración Docker ├── requirements.txt └── main.py
4. Justificación de la arquitectura
La separación en capas permite aislar cambios y mejorar la mantenibilidad. La capa de API se encarga exclusivamente de la exposición de servicios, mientras que la lógica de negocio se centraliza en servicios independientes.
El módulo de datos permite desacoplar el acceso a base de datos, facilitando cambios futuros en la tecnología utilizada.
La inclusión de un módulo ETL permite integrar procesamiento de datos, aspecto clave en entornos Big Data.
5. Preparación para entornos reales
- Contenerización mediante Docker.
- Integración con pipelines CI/CD.
- Escalabilidad mediante servicios distribuidos.
- Posibilidad de integración con Kafka para streaming.
6. Conclusión
Una correcta estructura inicial reduce la deuda técnica y permite evolucionar el sistema hacia arquitecturas más complejas sin necesidad de rediseños completos.
Este diseño servirá como base para la construcción progresiva de una plataforma completa en Python.